

AWS Solutions Architect

En esta práctica cloud veremos como construir microservicios dentro de AWS siguiendo el paradigma serverless. Este tipo de solución permite disponer de sistemas completamente administrados por AWS donde nosotros no deberemos preocuparnos por disponibilizar los recursos o administrarlos, simplemente especificaremos dentro de su configuración las políticas de ejecucion y escalado si se necesitasen, el pago por tanto es exclusivamente por uso.
Para poder realizar esta práctica deberemos disponer de las siguientes instalaciones que nos permitirán poder desarrollar los microservicios y operar el entorno.
Se plantea un escenario donde diferentes usuarios mediante aplicaciones multiplataforma acceden a diferentes recursos dentro de la app consumiendo una API Rest segura desplegada en AWS, para ello deberán en primer lugar autenticarse contra el pool de cognito para obtener un token JWT que les permitirá consumir los diferentes endpoints de la API.
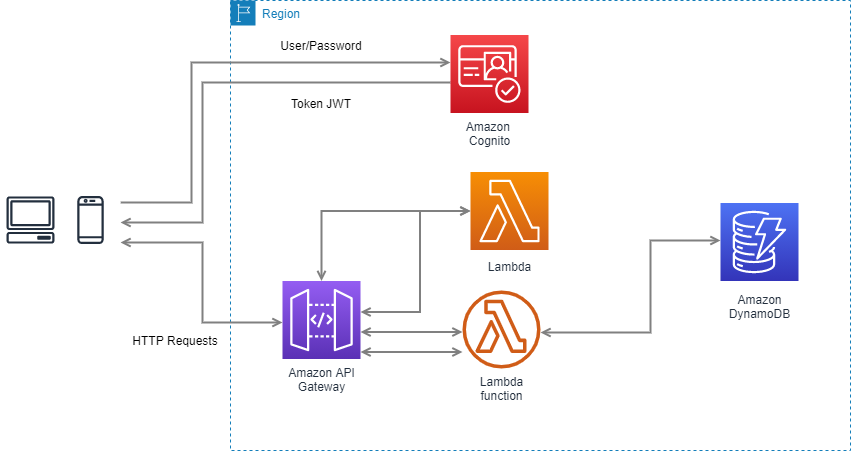
Para poder ofrecer seguridad a la API y que sus servicios solo sean consumidos por usuarios autorizados, debemos emplear un broker que nos pueda ofrecer autenticacion y a su vez autorizacion sobre estos servicios.
En primer lugar deberemos de entender el flujo que sigue un usuario para poder ser autenticado y autorizado para consumir un microservicio. En el siguiente diagrama se pueden ver como en una serie de pasos un usuario puede consumir el endpoint.

Json Web Token es un estándar abierto (RFC 7519) donde se define una forma autónoma de asegurar integridad en los datos enviados gracias a que va firmada digitalmente con HMAC (firma simetrica – misma clave) o RSA(firma asimetrica – par de claves privada/publica) y asi asegurar que el peticionario es una entidad segura. Además estos tokens pueden estar encriptados adicionalmente para ocultar los reclamos a terceros. El escenario principal donde se emplea es en la autorización del peticionario.
Cada token JWT consta de tres partes separados por un “.” de la forma header.payload.signed codificados en base64 por separado.
Header: Indica el tipo de token y su firma, en el caso de RS256 incluirá el kid que identifica la clave pública del emisor del Token que se empleara para verificar la firma. Mediante el iss del payload y el kid de la clave podremos ver en el navegador https:///.well-known/jwks.json la firma publica empleada para descifrar el token.
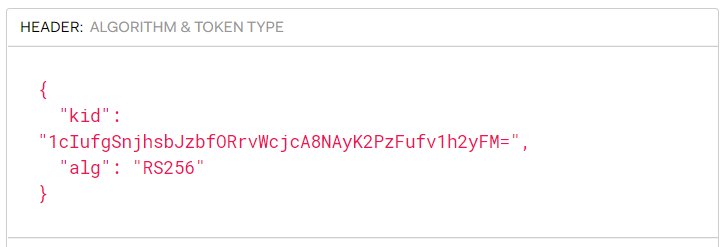
Payload: Contiene los claims que permiten verificar los atributos de la generación del token: iss (emisor), aud (audience), exp( expiracion) y otros campos que se puedan añadir adicionalmente para enviar información.
Cognito es un servicio completamente administrado que ofrece autenticación de usuarios para aplicaciones multiplataforma, además permite el empleo de identidades federadas como Google, Amazon, Facebook, etc para su registro.
Los usuarios podrán registrarse y loguearse contra un pool de usuarios que funciona como directorio de usuarios donde serán albergados los parámetros de autenticación: email, password, número de teléfono, etc. Se ofrecen además opciones de confirmación de usuario mediante código o enlace vía email o sms. Los usuarios autenticados recibirán un token de acceso que podrán emplear para recibir autorización a los microservicios de Api Gateway. Mediante otras opciones no planteadas en este caso de uso, se podrá recibir credenciales temporales STS de AWS para acceder directamente a servicios AWS mediante la función AssumeRoleWithWebIdentity mediante los pool de identidades.
Los usuarios emplearan la interfaz web de Cognito para autenticarse y recibir un código que podrán intercambiar por un token JWT que emplearán como autorización en los microservicios desplegados en Api Gateway.
Empezaremos creando nuestro pool de usuarios.
resource "aws_cognito_user_pool" "user_pool" {
name = var.cognito.user_pool_name
auto_verified_attributes = ["email"]
username_attributes = ["email"]
verification_message_template {
email_subject_by_link = "APP Notification - Account Verification"
email_message_by_link = "Please click the link to verify your email address: {##VERIFY EMAIL##}\n<br><br>\n"
default_email_option = "CONFIRM_WITH_LINK"
}
email_configuration {
email_sending_account = "COGNITO_DEFAULT"
}
account_recovery_setting {
recovery_mechanism {
name = "verified_email"
priority = 1
}
}
} Por otro lado, activaremos la interfaz propia de AWS a modo de pruebas para poder realizar el proceso de autenticado contra cognito sin tener que realizar un desarrollo del frontend propio.
resource "aws_cognito_user_pool_client" "client" {
name = var.cognito.app_client_name
user_pool_id = aws_cognito_user_pool.user_pool.id
supported_identity_providers = ["COGNITO"]
callback_urls = var.cognito.callback_urls
allowed_oauth_flows_user_pool_client = var.cognito.user_pool_client
allowed_oauth_flows = ["code"]
allowed_oauth_scopes = ["openid","email"]
}
resource "aws_cognito_user_pool_domain" "main" {
domain = var.cognito.domain_name
user_pool_id = aws_cognito_user_pool.user_pool.id
} En Api Gateway configuraremos un autorizador que recibirá el token JWT y comprobará la firma del token, como el emisor y audiencia añadidos en los propios scopes. El proceso de comprobación es automático permitiendo el acceso directo al servicio si este es válido o denegando mediante un unauthorized la request.
resource "aws_apigatewayv2_authorizer" "jwtAuth" {
api_id = aws_apigatewayv2_api.api.id
authorizer_type = "JWT"
identity_sources = ["$request.header.Authorization"]
name = var.api.jwt_authorizer_name
jwt_configuration {
audience = [aws_cognito_user_pool_client.client.id]
issuer = "https://${aws_cognito_user_pool.user_pool.endpoint}"
}
} En primer lugar, deberemos abrir la interfaz proporcionada por Cognito para realizar los procesos de sign-up, sign-in. La podremos encontrar dentro de la consola de AWS, en el servicio de Cognito, dentro de la configuración del cliente de aplicación “Lanzar interfaz de usuario alojada”.
1. Procederemos a registrar un usuario
2. Nos pedira que confirmemos el usuario a través del enlace enviado a nuestra cuenta de correo introducida.
3. El correo recibido tendrá la siguiente forma:
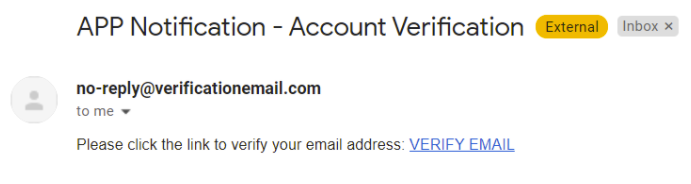
4. Accedemos al enlace de VERIFY EMAIL
5. Finalmente tendremos ya nuestro usuario confirmado en nuestro pool de usuarios de Cognito.

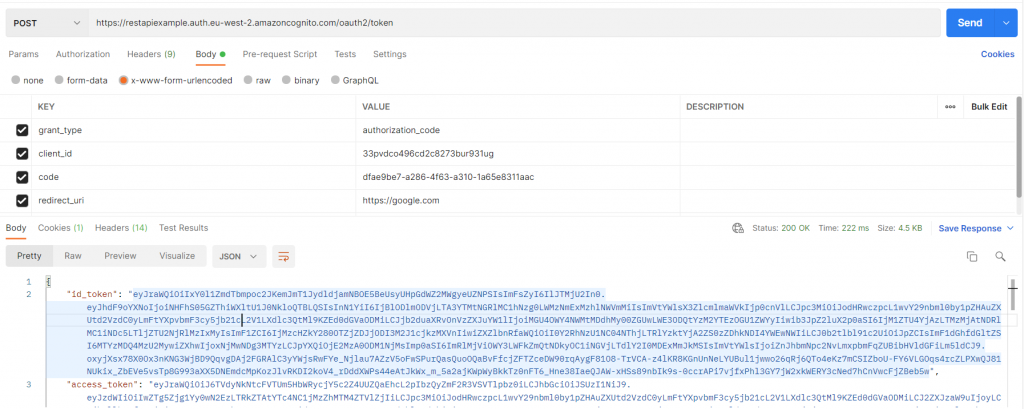
6. Procedemos a logearnos en la interfaz de AWs empleada anteriormente y si los credenciales son correctos nos devolverá a la url de callback configurada cuando hemos creado el pool de usuarios con Terraform junto a un code que emplearemos posteriormente para obtener el token.
Obtendremos como respuesta el identity token (id_token) que contiene toda la informacion personal del usuario y es el que generalmente se empleará para la autorización y el access_token empleado principalmente para llamar a servicios externos sin incluir informacion personal del usuario. Dependiendo del caso de uso, si realmente la información aportada por el identity token no es necesaria, es recomendable emplear el access_token. Por ultimo el refresh token, se emplea principalmente para obtener un identity o access tokens nuevos.
Los microservicios seran desplegados en Api Gateway y tendrán como backend Lambda integrada como proxy y DynamoDB como bbdd. Todos estos servicios funcionan de forma completamente administrada siguiendo los objetivos serverless de esta práctica.
Vamos a definir brevemente estos servicios y ver cual es su papel dentro de la arquitectura.
Mediante Api Gateway podremos desarrollar APIs de una forma sencilla, segura y escalable, ademas de ofrecernos la integración con Lambda para poder operar sin aprovisionamiento. Solo funciona con HTTPs
Dispone de integración proxy para exponer por completo el request como input al backend. En el caso concreto del workshop se empleará Lambda Proxy Integration para poder consumir los parámetros desde el handler de la función vía el evento, para ello deberemos definir en la etapa de implementación POST como tipo, independientemente de que definamos el metodo HTTP del endpoint como GET.
Api Gateway es compatible con CloudFront como de CDN de la API, además es posible incorporar WAF como servicio de mitigación de ataques DDoS.
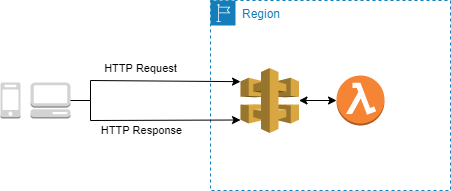
AWS actualmente dispone de dos versiones de Api Gateway, nosotros desplegaremos la última version, v2.
¿Que diferencias podemos encontrar? Los principales cambios introducidos con la version 2, se basan en:
Para poder crear nuestra Api deberemos crear los siguientes recursos
resource "aws_apigatewayv2_api" "api" {
name = var.api.api_name
protocol_type = "HTTP"
}
resource "aws_cloudwatch_log_group" "api_gw" {
name = "/aws/api_gw/${aws_apigatewayv2_api.api.name}"
retention_in_days = 30
}
resource "aws_apigatewayv2_stage" "stage" {
api_id = aws_apigatewayv2_api.api.id
name = var.api.stage_name
auto_deploy = true
access_log_settings {
destination_arn = aws_cloudwatch_log_group.api_gw.arn
format = jsonencode({
requestId = "$context.requestId"
sourceIp = "$context.identity.sourceIp"
requestTime = "$context.requestTime"
protocol = "$context.protocol"
httpMethod = "$context.httpMethod"
resourcePath = "$context.resourcePath"
routeKey = "$context.routeKey"
status = "$context.status"
responseLength = "$context.responseLength"
integrationErrorMessage = "$context.integrationErrorMessage"
}
)
}
} Una vez creada la Api, crearemos los dos endpoints que emplearemos en este workshop: GET,POST
Para ambos indicaremos:
GET
#### GET
resource "aws_apigatewayv2_integration" "get_item_app_integration" {
api_id = aws_apigatewayv2_api.api.id
integration_type = "AWS_PROXY"
description = "Lambda GET example"
integration_method = "POST"
integration_uri = aws_lambda_function.get_item_app.invoke_arn
}
resource "aws_apigatewayv2_route" "get_item_app_route" {
api_id = aws_apigatewayv2_api.api.id
route_key = "GET /user"
target = "integrations/${aws_apigatewayv2_integration.get_item_app_integration.id}"
authorization_type = "JWT"
authorizer_id = aws_apigatewayv2_authorizer.jwtAuth.id
}
resource "aws_lambda_permission" "get_item_app_execution" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.get_item_app.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.api.execution_arn}/*/*"
} POST
resource "aws_apigatewayv2_integration" "create_item_app_integration" {
api_id = aws_apigatewayv2_api.api.id
integration_type = "AWS_PROXY"
description = "Lambda example"
integration_method = "POST"
integration_uri = aws_lambda_function.create_item_app.invoke_arn
}
resource "aws_apigatewayv2_route" "create_item_app_route" {
api_id = aws_apigatewayv2_api.api.id
route_key = "POST /user"
target = "integrations/${aws_apigatewayv2_integration.create_item_app_integration.id}"
authorization_type = "JWT"
authorizer_id = aws_apigatewayv2_authorizer.jwtAuth.id
}
resource "aws_lambda_permission" "create_item_app_execution" {
statement_id = "AllowExecutionFromAPIGateway"
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.create_item_app.function_name
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.api.execution_arn}/*/*"
} Para el desarrollo de la lógica de nuestros microservicios emplearemos AWS Lambda, servicio de computación completamente administrado con escalado automático. Donde se definen unos recursos de memoria y CPU para realizar la ejecución de cada función. Soporta de forma nativa lenguajes como Java, NodeJS, Python, etc. Las funciones son albergadas en un paquete de implementación del tipo zip alojadas en un bucket de S3 interno o creado por nosotros.
En primer lugar, crearemos el rol de ejecución, donde además definiremos que acciones se pueden ejecutar dentro de estas y sobre que servicios, en nuestro caso simplemente permitiremos acciones CRUD sobre la tabla DynamoDB especifica que crearemos posteriormente.
resource "aws_iam_role" "lambda_exec_dev" {
name = "serverless_lambda_dev"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [{
Action = "sts:AssumeRole"
Effect = "Allow"
Sid = ""
Principal = {
Service = "lambda.amazonaws.com"
}
}
]
})
}
resource "aws_iam_role_policy_attachment" "lambda_policy_attachment_dev" {
role = aws_iam_role.lambda_exec_dev.name
policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"
}
resource "aws_iam_role_policy_attachment" "lambda_dynamodb_policy_attachment_dev" {
role = aws_iam_role.lambda_exec_dev.name
policy_arn = aws_iam_policy.lambda_dynamodb_policy_dev.arn
}
resource "aws_iam_policy" "lambda_dynamodb_policy_dev" {
name = "lambda_dynamodb_policy_dev"
description = "Lambda DynamoDB access"
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = [
"dynamodb:Query",
"dynamodb:GetItem",
"dynamodb:PutItem",
"dynamodb:UpdateItem",
"dynamodb:BatchWriteItem",
"dynamodb:BatchGetItem",
]
Effect = "Allow"
Resource = [aws_dynamodb_table.app_table.arn]
},
]
})
depends_on = [aws_dynamodb_table.app_table]
} Las funciones irán recogidas en un zip con el codigo Python que será subido a un bucket interno que crearemos expresamente para albergarlas. En cada función indicaremos su handler, runtime, rol de ejecución y el bucket/objeto donde poder encontrar el paquete de funciones.
data "archive_file" "lambda_functions_package" {
type = "zip"
source_dir = "${path.module}/scripts/"
output_path = "${path.module}/scripts/crud_lambdas.zip"
}
resource "aws_s3_bucket_object" "lambda_functions_package_object" {
bucket = aws_s3_bucket.internal_dev.bucket
key = "crud_lambdas.zip"
source = data.archive_file.lambda_functions_package.output_path
etag = filemd5(data.archive_file.lambda_functions_package.output_path)
}
resource "aws_s3_bucket" "internal_dev" {
bucket = var.bucket_name
acl = "private"
} Para su creacion simplemente indicaremos el nombre de la función Lambda, rol de ejecución, runtime, la función de ejecucíon, el bucket y el zip donde estan alojadas.
resource "aws_lambda_function" "get_item_app" {
function_name = "get_user"
handler = "get_user.lambda_handler"
runtime = "python3.6"
s3_bucket = aws_s3_bucket.internal_dev.bucket
s3_key = aws_s3_bucket_object.lambda_functions_package_object.key
source_code_hash = data.archive_file.lambda_functions_package.output_base64sha256
role = aws_iam_role.lambda_exec_dev.arn
}
resource "aws_lambda_function" "create_item_app" {
function_name = "create_user"
handler = "create_user.lambda_handler"
runtime = "python3.6"
s3_bucket = aws_s3_bucket.internal_dev.bucket
s3_key = aws_s3_bucket_object.lambda_functions_package_object.key
source_code_hash = data.archive_file.lambda_functions_package.output_base64sha256
role = aws_iam_role.lambda_exec_dev.arn
} Estas funciones Python emplearán la librería boto3 para poder realizar de una forma sencilla y rápida el conector contra la tabla de DynamoDB, estarán alojadas bajo el directorio de /scrips.
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('AppDummy') A partir de este conector mediante table.get_item() o table.create_item() podremos realizar nuestras operaciones GET y POST respectivamente. Si la acción se ejecuta correctamente lanzaremos un codigo 200 y devolveremos el objeto añadido/obtenido.
item = json.loads(event["body"])
user = item["User"]
...
table = dynamodb.Table('AppDummy')
response = table.put_item(
Item=user
)
... id = str(event["queryStringParameters"]['UserId'])
...
response = table.get_item(
Key={
'UserId': id
}
)
... Por último, crearemos una tabla básica para albergar los atributos de nuestros usuarios, tendrá simplemente como PK el id de usuario en string para soportar alfanuméricos.
resource "aws_dynamodb_table" "app_table" {
name = "AppDummy"
billing_mode = "PAY_PER_REQUEST"
hash_key = "UserId"
attribute {
name = "UserId"
type = "S"
}
} Mediante Terraform desplegaremos nuestra infraestructura, primero deberemos lanzar un init que descargará los plugins y inicializará nuestro directorio de trabajo con los archivos de configuración de AWS, para posteriormente ejecutar un plan, si el despliegue de recursos planificado por el plan concuerda con lo que buscamos finalmente ejecutaremos un apply para desplegar toda nuestra infra y realizar las pruebas.
En esta práctica, nuestro estado permanecera en local, no configuraremos AWS como backend para los estados de Terraform
terraform init
terraform plan -var-file="env/dev.tfvars"
terraform apply -var-file="env/dev.tfvars" Una vez desplegado nuestro proyecto, comprobaremos el correcto funcionamiento de los microservicios que hemos programado. Además en ambos casos, deberemos añadir el campo authorization en el header de la peticion HTTP con el prefijo Bearer y el access_token obtenido anteriormente para poder ser autorizados a consumir el microservicio.

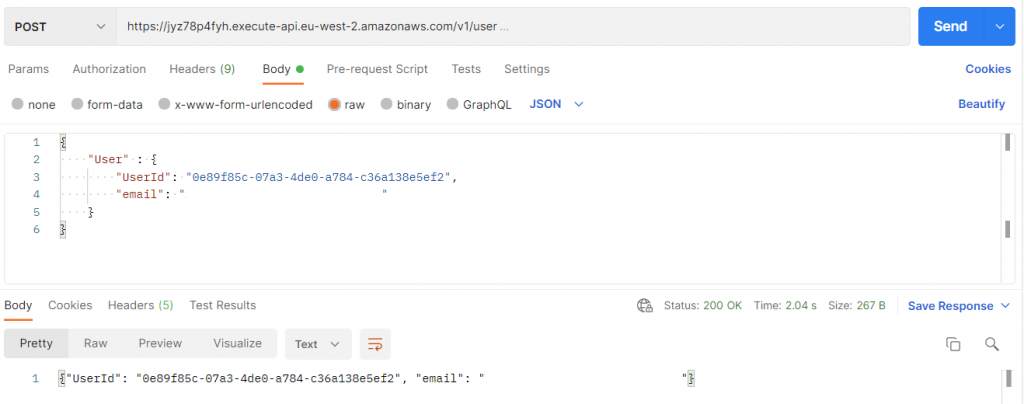
POST /user
En primer lugar, probaremos la peticion HTTP POST /user, debería añadir el usuario a la tabla de DynamoDB creada y enviando como respuesta un codigo 200 y el usuario añadido a la tabla.
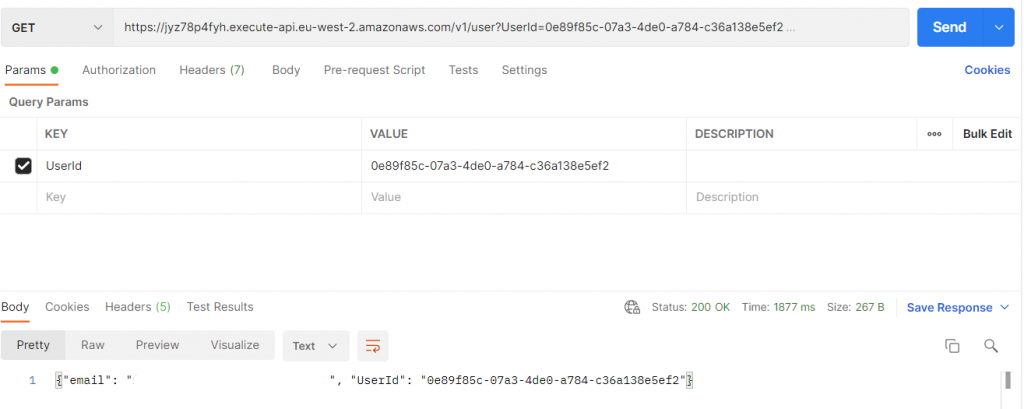
GET /user
De la misma forma, consumiremos el microservicio que a partir del UserId nos devolverá la información del usuario, recordando que al ser una petición GET la información relativa a la consulta irá en el Query Params (propia url)
En esta práctica hemos podido aprender a como desarrollar una API Rest segura y completamente administrada dentro del entorno de AWS, sirviendonos de la última versión de Api Gateway que facilita la integración nativa con autorizadores de JWT.
La integración de Cognito con Api Gateway nos torga la capa de seguridad y administración de los usuarios. Respectivamente con Lambda y DynamoDB disponemos de la capa de lógica/persistencia de nuestra API. La integración nativa de todos estos servicios nos facilita el desarrollo de estas aplicaciones al disminuir la carga de trabajo dedicada tanto al desarrollo puro, como a la integracion de los distintos servicios involucrados y su administración, además gracias a Terraform disponemos de toda la infraestructura como código facilitando su futura evolución y disponibilización en otros entornos de una forma mucho más rápida y comprensible.
En futuras entradas veremos como desarrollar otros escenarios típicos que podemos encontrar en nuestro día a día dentro de AWS, con el fin de tener unas primeras herramientas para poder solventar futuros escenarios que se nos planteen.
Espero que la práctica haya sido de vuestro agrado e interés, os espero en futuras entregas!
AWS Solutions Architect
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar




