
- Saltar a la navegación principal
- Saltar al contenido principal
- Saltar a la barra lateral principal
- Saltar al pie de página
Bluetab
an IBM Company
LakeHouse Streaming en AWS con Apache Flink y Hudi (Parte 2)

Introducción
Este artículo es el segundo en una serie de publicaciones que se centran en la creación de un LakeHouse con Hudi a partir de una ingesta en streaming procesada por una aplicación Flink. El primer artículo se centra en sentar una buena base para esta plataforma, donde se desplegaron unas aplicaciones Flink con KDA (Kinesis Data Analytics) para cada tipo de formato (MoR, CoW para Hudi y JSON) que escriben el resultado de este procesamiento en unos buckets.
El envío de datos que se utiliza como input se mandaba en el anterior artículo desde una máquina en local ejecutando una aplicación de Locust, lo que puede presentar problemas a la hora de escalar y querer procesar un volumen alto de eventos. Además, las aplicaciones de Kinesis Data Analytics con Flink presentan problemas de agilidad en su modo de autoescalado. Todos estos nuevos retos serán resueltos en este artículo.
También se catalogarán estas tablas en Glue, servicio que disponibiliza un catálogo de datos en AWS, para poder acceder a estos y así realizar queries de todo tipo. Como motor de queries que consumirá estos metadatos se utilizará Athena, que proporciona una experiencia escalable, ágil y serverless para poder ejecutar queries con SQL o Spark para nuestras tablas alojadas en S3.
Por otro lado, en este artículo también se han desplegado los componentes necesarios para poder monitorizar nuestras aplicaciones y extraer así conclusiones sobre la velocidad a la que se ingestan los datos y los posibles problemas a resolver para que el procesamiento tenga la latencia requerida según los requisitos que se impongan.
Finalmente se realizará una comparativa en cuanto a rendimiento y latencia de las diferentes aplicaciones de Flink que escriben datos en los formatos de Hudi y JSON para así poder ver las diferentes ventajas e inconvenientes de estos formatos.
Arquitectura
A continuación se puede ver la arquitectura a alto nivel que se desplegará:
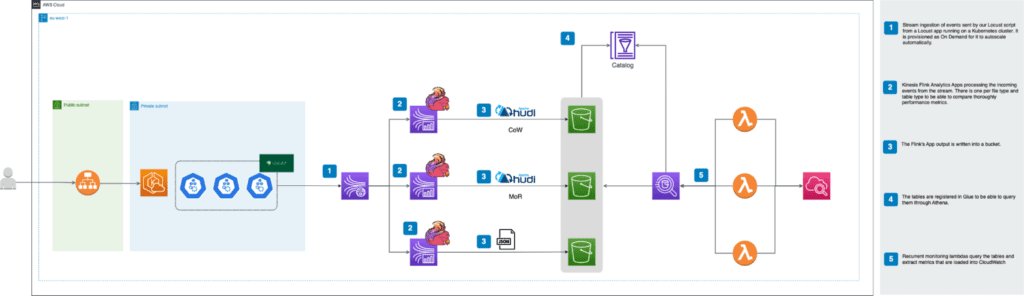
Para un mayor entendimiento vamos a explicarla de izquierda a derecha. Como se puede observar, el cambio más reseñable con respecto al primer artículo es la inclusión de un cluster de Kubernetes para poder escalar los eventos que serán mandados como input de nuestra aplicación de streaming. De esta manera se podrá testear de manera exhaustiva el rendimiento de las aplicaciones de Flink dependiendo de su aprovisionamiento y sobre todo del tipo de formato y tabla en el que escriben al LakeHouse. Además, se ha disponibilizado un ALB (Application Load Balancer) que permite acceder a la interfaz de Locust para poder definir el número de usuarios a simular y cómo deben escalar estos con el tiempo. La URL para acceder a esta aparecerá como output al desplegar la infraestructura con Terraform.
Por otro lado se han realizado cambios reseñables en las aplicaciones KDA de Flink y el stream del que leen estas. Cada aplicación lee ahora como consumidores EFO (Enhanced Fan Out), de tal manera que cada una de ellas tiene un ancho de banda dedicado. La razón de este cambio y sus detalles serán explicados más en detalle en el apartado dedicado para Kinesis.
En cuanto a la monitorización y la extracción de métricas en NRT (Near Real Time) se han desplegado unas funciones lambdas que acceden a las tablas apoyándose en Athena gracias a haber registrado los metadatos de estas en el catálogo de Glue. Es importante resaltar que los metadatos de las tablas de Hudi son registrados en Glue por Flink pero en el caso de JSON se despliega un crawler que registra estas tablas en el catálogo. Este crawler se debe ejecutar manualmente para que esta tabla quede registrada en Glue.
Escalado
Kinesis Stream
Dado que el objetivo es someter la aplicación a una carga considerable de eventos por segundo, es necesario explicar cómo cada una de las piezas de la arquitectura pueden escalar de acuerdo al volumen de datos.
Como hemos comentado previamente, se ha optado por un Kinesis Stream On-Demand para automatizar el escalado de los shards durante las pruebas de carga. Es necesario tener en cuenta que estos streams pueden acomodar una tasa de escritura de hasta el 200% de lo especificado por el número de shards en un momento dado.
Una vez que el stream se encuentra por encima del 100%, aumentará automáticamente el número de shards en un plazo de 15 minutos. La única limitación por tanto es no superar el doble del volumen de escritura admitido en menos de dicho periodo.
Por otro lado, dado que se tendrán tres aplicaciones de Flink leyendo del mismo stream, las limitaciones a nivel de lectura serán el mayor problema. Un Kinesis Stream solo admite 5 llamadas GetRecord por shard por segundo. Dado que cada aplicación tiene que leer todo el stream (y por lo tanto, todos los shards), aumentar el número de shards no ayuda a solventar este problema.
La solución pasa por registrar cada una de las aplicaciones como un consumidor Enhanced Fan-Out. Esta funcionalidad de los Kinesis Stream provee a cada uno de estos consumidores con un límite individual de 5 llamadas GetRecord y 2MB por shard por segundo de lectura.
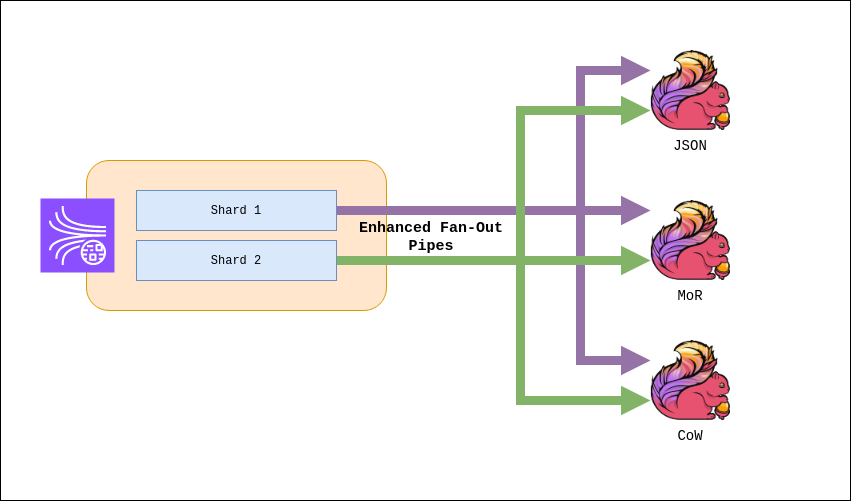
Esta configuración se realiza en el lado del consumidor, en nuestro caso mediante el conector de Kinesis para Flink:
'scan.stream.recordpublisher' = 'EFO',
'scan.stream.efo.registration' = 'EAGER/LAZY',
'scan.stream.efo.consumername' = '{consumer_name}' Conviene mencionar que alternativamente, es posible aumentar la latencia de lectura de nuestras aplicaciones de Flink. Por defecto Flink realiza una lectura cada 200 ms por shard, de modo que una aplicación consume completamente la cuota de lectura de un stream. Incrementando este valor a 600ms podríamos acomodar las tres aplicaciones, a costa de una mayor latencia:
scan.shard.getrecords.intervalmillis = '600' También se hará uso de la opción Adaptive Reads, que modifica dinámicamente el número de eventos recogidos por llamada en función del tamaño de cada record. Esto permite aprovechar los 2 MB/s por shard disponibles para cada consumidor:
'scan.shard.adaptivereads' = 'true' En lo que respecta al escalado en KPUs (Kinesis Processing Unit) de Flink, se ha optado por no hacer uso del autoescalado, ya que cada proceso de escalado incurren en downtime para la aplicación. Debido a los diferentes requerimientos de cada una de las aplicaciones, las acciones de escalado en momentos inesperados podrían interrumpir las pruebas de carga. Además es interesante medir el rendimiento de escritura de cada una de las aplicaciones en igualdad de capacidad de computación.
Hudi
Timeline
Uno de los sistemas base sobre la que se sustenta el funcionamiento y características de Hudi es la timeline. Hudi guarda un registro temporal de todas las acciones que se han realizado sobre la tabla, así como el estado de esta acción.
Las principales acciones que componen la timeline son
- Commits – escritura atómica de un conjunto de registros en la tabla en formato columnar
- Delta Commit – similar al commit, representa una escritura de registros en forma de logs en una tabla Merge on Read
- Compaction – compactación de las escrituras en logs (delta commits) de una tabla MoR a formato columnar
- Cleans – borrado de versiones antiguas de archivos
- Rollback – eliminado de los registros escritos por un commit o delta commit fallido
- Savepoint – marca un conjunto de archivos como “guardados” para que no sean eliminados por el proceso de limpieza. Permite restaurar la tabla a un punto anterior en la timeline
Cualquiera de estas acciones pueden encontrarse en uno de estos tres estados
- Requested – una acción ha sido planeada sin iniciar
- Inflight – la acción está en proceso
- Completed – denota que la acción ha sido completada
Tipos de tabla
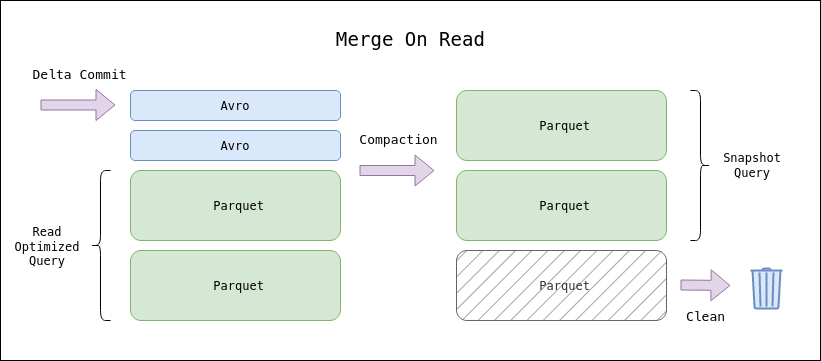
Como se ha dejado entrever en el funcionamiento de la timeline de Hudi, existen dos tipos de escritura soportados: columnar y logs. El formato columnar (parquet) constituye la forma final de una tabla de Hudi, junto con los metadatos de la timeline. Sin embargo, es posible hacer uso de las escrituras en logs (avro) para disminuir la latencia de escritura y eventualmente compactarse a formato columnar sin entorpecer la escritura.
El uso de estos métodos de escritura dan lugar a los dos tipos de tabla que Hudi pone a nuestra disposición
- Copy on Write – las escrituras se realizan exclusivamente en formato columnar, creando un nuevo fichero con los nuevos registros de la tabla. Los datos están disponibles inmediatamente pero incurre en mayor latencia de escritura
- Merge on Read – hace uso de la escritura en logs. Los nuevos registros son inicialmente escritos como logs, y posteriormente serán transformados a formato columnar por el proceso de compactación. Obtenemos menor latencia de escritura a costa de latencia de lectura; los nuevos registros no estarán disponibles hasta que se realice la compactación.
Tipos de Query
Para poder aprovechar las características de cada tipo de tabla, existen tres tipos de queries que se pueden realizar sobre una tabla de Hudi
- Snapshot – obtiene la última versión de la tabla. Para las tablas MoR esto implica incurrir en un proceso de compactación para obtener los últimos registros en formato log.
- Read Optimized – para tablas MoR, lee sólamente los registros ya expuestos en formato columnar sin incurrir en latencia de lectura adicional.
- Incremental – recoge únicamente los nuevos registros desde un cierto commit o compactación, facilitando la creación de pipelines incrementales. No está soportada por Athena
Integración con Glue Catalog
El conector de Hudi permite una integración nativa con el catálogo de Glue en AWS. Basta con añadir las dependencias de Hive en nuestra aplicación de Flink:
com.amazonaws.aws-java-sdk-glue
org.apache.hive.hive-common
org.apache.hive.hive-exec Y especificar la configuración del catálogo en el conector de Hudi:
'hive_sync.enable' = 'true',
'hive_sync.db' = '{glue_database}',
'hive_sync.table' = '{table_name}',
'hive_sync.partition_fields' = '{partition_fields}',
'hive_sync.mode' = 'glue',
'hive_sync.use_jdbc' = 'false' Con esta integración, la aplicación creará automáticamente las tablas en el catálogo. Como hemos mencionado anteriormente, existen distintos tipos de query para consultar una tabla de Hudi. Se crearán por tanto en el catálogo distintas tablas para soportar las diferentes consultas.
Para una tabla CoW, la tabla se consultará mediante una query Snapshot. Para MoR en cambio se pondrán a disposición dos tablas, para soportar consultas Read Optimized o Snapshot.
La principal aplicación de Glue es de soporte a las lambdas para que al ejecutar las queries mediante Athena su ejecución pueda realizarse de una forma más eficiente, rápida y segura:
- Glue Catalog: almacenamiento centralizado de la información acerca de la organización, diseño y formato de los datos, utilizado por Athena para realizar directamente las consultas a S3 sin necesidad de tener que apoyarse en terceros para conseguir esta información
- Automatización del Esquema: Glue rastrea y cataloga automáticamente los datos en S3, detectando y adaptando los cambios en el esquema. Esto evita posibles errores y permite la lectura de los nuevos campos en caso de que se produzcan alteraciones en los esquemas de los eventos
Configuración de Hudi
Es importante entender las configuraciones que nos ofrece Hudi para optimizar nuestra aplicación, en particular para una aplicación en Near Real Time conviene estar al tanto de las opciones disponibles. Aunque la capacidad de configuración es inmensa [1], se intentará sintetizar las que pueden ser más relevantes para una primera toma de contacto con esta tecnología.
Particionado
Apache Hudi ofrece los tipos de particionado que pueden encontrarse en otras soluciones, se detallarán las principales y se justificara la implementada:
- Simple: particionado basado en un único campo, en este caso el campo escogido es ‘ticker’ ya que se ha identificado que es el que tiene una cardinalidad menor.
- Particionado Compuesto: particionamiento basado en múltiples campos, podría resultar interesante escoger un campo de baja cardinalidad (ticker) y otro de cardinalidad media (fecha)
- Particionado Dinámico: elección de la variable en base de los valores, puede resultar interesante cuando la cardinalidad de las variables puede sufrir variaciones y se quiera una actualización del particionamiento de una forma automática y flexible.
Índices
Apache Hudi cuenta con una múltiples tipos de indexación[2], comentaremos brevemente los más comunes:
- Bloom Index – Hace uso de un bloom filter sobre la key de los eventos, adicionalmente se puede complementar con un filtrado por rango de de key. Funciona bien cuando tratamos con una tabla donde la mayoría de cambios ocurren en las particiones más recientes o para deduplicado de eventos.
- Simple: indexación realizada mediante la combinación de FileID y RecordKey. Recomendado cuando las operaciones Upsert no son tan frecuentes debido a la simplicidad que este ofrece.
Ambos tipos de índices pueden ser usados en su forma global
- Índice global – Imponen la unicidad de las keys en todas las particiones de la tabla, es decir, garantizan que existirá sólamente un registro con una cierta key.
- Índice no global – La unicidad de la key sólo es exigida a nivel de partición. Si los datos son consistentes y una key sólo va a existir en una partición, este tipo de índices ofrecen un rendimiento mucho mayor y mejor escalado.
En este caso, se ha optado por un Bloom Index, el cual es el que se toma por defecto en caso de que no se declare expresamente:
"hoodie.index.type" = "BLOOM" La elección de este tipo de indexación se debe a que los casos de uso que se han planteado requieren de un procesamiento de datos considerablemente alto y eficiente.
Tipos de operación
Apache Hudi ofrece varios tipos de operaciones[3] que permiten a los usuarios administrar y modificar conjuntos de datos de gran tamaño. A continuación se detallan tanto las principales operaciones realizadas en los Stress Tests como en otros escenarios:
- Upsert – Es la operación por defecto, y ejecutará un insert o un update dependiendo de si el registro ya existe tras una búsqueda en el índice. Con esta operación la tabla no tendrá duplicados para su clave primaria.
- Insert – Esta operación ignora la búsqueda en el índice a la hora de insertar eventos. Es la más rápida pero la tabla puede contener duplicados. Aún así es útil si se utilizan métodos auxiliares de deduplicado, o simplemente la existencia de estos es tolerable en el caso de uso.
- Delete: Hudi ofrece dos métodos de borrado. Soft Delete convierte a nulos los valores del evento a excepción de la key. Hard Delete ejecuta un borrado físico del evento en la tabla.
- Bulk Insert Operación similar al Insert pero optimizada para la inserción de un gran volumen de datos, a costa de sacrificar ciertas garantías en el control del tamaño de ficheros. Escala bien para cientos de TBs en caso de bootstrap inicial de una tabla de gran tamaño.
Compactación
En el caso de usar una tabla MoR es posible configurar el ritmo de compactación de logs en parquet para buscar el equilibrio entre latencia de escritura y lectura que más convenga al caso de uso. Se pueden especificar una estrategia de tiempo o número de delta commits (o ambos) que ejecutan un proceso de compactación:
compaction.delta_commits
compaction.delta_seconds
compaction.trigger.strategy Acciones asíncronas
Ciertas acciones de la timeline como la compactación, limpieza, archivado y clustering pueden ser realizadas asíncronamente por la aplicación, o incluso ser relegadas a procesos auxiliares a la aplicación de escritura. Para el caso de Flink, puede ayudar a mejorar la latencia de escritura y evitar problemas de BackPressure en la aplicación:
compaction.async.enabled
hoodie.clean.async
hoodie.archive.async
hoodie.clustering.async.enabled Stress Tests & Insights
Al desplegar las aplicaciones, se ha procedido a realizar distintos tests variando tanto la carga máxima de eventos como la concurrencia y el grado exponencial de crecimiento de los mismos. Esto ha sido posible gracias a la flexibilidad ofrecida por Locust al estar levantado sobre un cluster de Kubernetes, pudiendo establecer un límite máximo de concurrencia de eventos y un incremental de los mismos. En los tests se ha establecido un límite máximo de 5 a 15K usuarios simultáneos (Peak Concurrency) escalando la frecuencia de los mismos de forma lineal, desde 5 a 20 usuarios más por segundo (Spawn Rate):
Se ha procedido a monitorizar los distintos test para así sacar conclusiones del rendimiento teniendo en cuenta las características específicas de cada uno de los formatos. Las métricas en las que se han apoyado los análisis son tanto las nativas de CloudWatch Metrics (CPU & Memory Utilization, KPUs, LastCheckpoint SIze & Duration,..), como las métricas obtenidas a partir de las Lambdas que periódicamente consultan el número de eventos disponibles en los buckets y realizan cálculos del promedio de la latencia de los mismos.
Número de Eventos

A la hora de analizar el número total de eventos procesados, los cuales son enviados de forma gradual, es decir, a medida que pasa el tiempo cada vez son más los eventos que se envían por segundo, se identifica una tendencia bastante similar aunque destacan JSON y Hudi MoR sobre Hudi CoW en cuanto a la rendimiento. Cabe destacar que JSON muestra un crecimiento más estable y constante en comparación con Hudi MoR y CoW y esto se debe a que estos últimos son capaces de manejar actualizaciones incrementales en los datos.
La similitud entre JSON y Hudi MoR hace que la elección se base completamente en las características del proyecto. En caso de que los datos no sean actualizados JSON puede resultar una solución más interesante debido principalmente a su simplicidad, mientras que si hay una alta frecuencia de actualización de datos históricos, Hudi MoR puede ser una mejor solución. Esto se debe tanto a la mayor eficiencia en las tareas de lectura como por la posibilidad de registrar las distintas versiones de los datos.
Latencia
Debido a la dificultad de estandarizar la lógica del cálculo de la latencia entre 3 tipos de almacenamiento distintos, se ha optado por simplificarla calculandolo como la diferencia entre la hora de creación del evento y la del procesamiento en la respectiva aplicación.

Se observa un comportamiento similar entre JSON y Hudi MoR, aunque este primero de una forma más crítica, al tener una latencia inicial muy baja pero a medida que tanto el tiempo de procesamiento como el volumen de carga aumenta, esta latencia se ve negativamente afectada.
La elección entre JSON y Hudi MoR dependerá tanto de la tolerancia de fallo que tenga la aplicación como las propias características de cada uno de los formatos, en caso de que la estructura de los datos sea estable y no cambie con frecuencia,o bien, no dependa de actualizaciones incrementales y pueda lidiar con reescrituras completas, en ese caso JSON puede que sea una mejor opción.
La elección de Hudi CoW sobre MoR puede darse cuando se necesite una alta tolerancia a errores y una alta capacidad de recuperación de eventos de escritura fallidos o corrompidos.`
Uso de CPU

Al analizar el uso de CPU, se ha identificado cierta homogeneidad entre los distintos tests aun trabajando con distintas cargas de trabajo. JSON Y Hudi MoR destacan por tener los niveles de uso de CPU más bajos, ambos por distintos motivos. JSON destaca por la simplicidad al incluir directamente los nuevos datos sin necesidad de tener que lidiar con versionado de datos, mientras que MoR no consume tanta CPU ya que por sus características, el consumo mayor de CPU se hace al realizar consultas de lectura, en las tareas de escritura únicamente identifica los cambios que serán aplicados al consultarlos.
Recordar que las métricas nativas de CloudWatch únicamente nos permiten monitorizar las aplicaciones, que corresponden a las tareas de escritura. La monitorización de las tareas de lectura corresponde a las Lambdas mencionadas anteriormente.
En este caso MoR es más beneficioso respecto a CoW, dado que el mayor consumo de CPU en MoR se produce al consultar los datos almacenados mientras que en CoW tiene lugar al actualizar los datos.
La elección entre los formatos más eficientes se deben a las necesidades del proyecto, en caso de que se requiera una mayor tolerancia al fallo, versionado de los datos y una mayor eficiencia de lectura, se optara por MoR frente a JSON, entre los dos formatos de Hudi, de nuevo, la elección dependerá de las características del proyecto, en caso de que las consultas requieran transformaciones pesadas y/o complejas se optaría por MoR, si en cambio, el proyecto requiera de una mayor integridad de datos y/o la ingesta de datos sea en batch, resultaría más interesante CoW debido a que al trabajar con esos volúmenes de datos, el contar con copias de seguridad, en caso de surgir errores, el impacto en término de costes y tiempo de recuperación es menor.
Memory Utilization

JSON de nuevo destaca por tener los valores de uso de memoria más bajos aunque para la operativa de transformaciones que se realizan son relativamente altos y más teniendo en cuenta que no tiene que lidiar con la administración de versiones o la combinación de datos. Estos valores se deben a que no tiene capacidades de compresión optimizadas ni manejo eficiente de esquemas.
Respecto a Hudi, se pueden obtener unas conclusiones similares a las del apartado de uso de CPU, MoR tiene una utilización de memoria mayor que JSON debido al procesamiento de logs delta y la administración de versiones y una menor a CoW ya que la consolidación real de los datos no ocurre durante la escritura.
Last Checkpoint Size

Destacar, nuevamente, la estabilidad de JSON frente a las aplicaciones Hudi, ya que no solo muestra en los test realizados un valor inferior a ambos, si no una estabilidad que no se consigue ni con MoR ni CoW, ya que como puede apreciarse, al monitorear el tamaño de los Checkpoints, se percibe una volatilidad considerable.
La volatilidad percibida en las aplicaciones Hudi se debe principalmente a fallos surgidos en Checkpoints lo que conlleva que el Checkpoint posterior al fallido, tenga un volumen mayor. Además de esto, la volatilidad en los tamaños de los Checkpoints puede estar relacionado con las operaciones de optimización y compactación realizadas internamente que puede conllevar la compactación del estado y que esto reduzca considerablemente el tamaño del mismo.
Desafíos en el desarrollo
Read Throughput de Kinesis y EFO
Para no sobrepasar el límite de lectura sobre el Kinesis Stream se ha optado por suscribir los consumidores como Enhanced Fan-Out. En algunas pruebas en conjunto con Autoscaling esto ha dado problemas con el conector de Kinesis de Flink siendo incapaces de cerrar conexiones a la hora de escalar el cluster.
Configuración de Hudi
La configuración de Hudi ha sido otro de los puntos de fricción durante el desarrollo. Bajo cargas elevadas los procesos de compactación y limpieza son más propensos a causar problemas de Backpressure y causar errores en la aplicación. Aunque configurar estos procesos para que ocurran de forma asíncrona puede aliviar este problema, pueden surgir conflictos y desalineación entre procesos bajo cargas elevadas. Un equilibrio entre estas configuraciones y la capacidad del cluster de la aplicación son claves para el buen funcionamiento de la aplicación.
Heterogeneidad de formato
Al hacer un análisis del rendimiento de las 3 aplicaciones, se cuenta con una dificultad adicional debido a la naturaleza de los tipos de formato, teniendo esto tanto un impacto a la hora de plantear la arquitectura como en el planteamiento de las lógicas.
El distinto comportamiento de los formatos en la ingesta, complica el desarrollo de las lógicas a la hora de calcular la latencia. MoR escribe en logs previa compactación, por lo que los datos no están disponibles inmediatamente como ocurre con CoW o JSON. Esto implica que la métrica común medible para todos los formatos es la de disponibilidad de lectura, la cual no es el principal objetivo de una tabla MoR.
Sincronización con el Glue Catalog
Una de las grandes ventajas que nos hemos encontrado con Hudi es su capacidad para sincronizarse con el catálogo de Glue, creando las tablas y manteniéndose actualizadas sin necesidad de un crawler. Esto permite una aplicación y arquitectura más limpia que para el caso de JSON, para el cual debe ejecutarse manualmente al desplegar las aplicaciones.
Conclusiones
Los resultados de los tests muestran diferencias considerables entre los formatos JSON, Hudi MoR y CoW en términos de eficiencia, capacidad de respuesta y utilización de recursos. Se procede a analizar cada uno de los aspectos más en detalle:
- Eficiencia de Procesamiento: JSON y Hudi MoR destacan en la mayoría de las métricas, mostrando un desempeño óptimo en términos de Latencia, CPU & Memory Utilization. Sin embargo, el comportamiento de JSON es más estable y predecible, aunque MoR cuente con ventajas sobre JSON, como por ejemplo, en la gestión de actualizaciones incrementales.
- Resiliencia y Tolerancia a Fallos: la tolerancia a fallos es un factor muy importante en la decisión sobre la elección entre Hudi y JSON. En el caso de MoR y CoW, dependerá del grado de criticidad, ya que a nivel general el rendimiento en tareas de escritura para MoR es superior.
- Uso de Recursos: JSON se muestra como el más ligero, con baja utilización de CPU y memoria, debido a su simplicidad inherente. Mientras que Hudi MoR y CoW, por la naturaleza de su diseño y gestión de datos, requieren más recursos, especialmente en operaciones que involucran el manejo de versiones y la compactación de datos.
Para finalizar, resulta interesante identificar en quéque casos de uso o proyectos puede resultar más recomendable cada uno de los formatos en función de las características de los mismos y las red flags que puedan establecerse:
- JSON: Recomendado para aplicaciones con estructuras de datos estables que no requieren actualizaciones incrementales y donde la simplicidad y la estabilidad son clave.
- Hudi MoR: Adecuado para proyectos que requieren una gestión eficiente de actualizaciones incrementales y donde la latencia y la eficiencia en la escritura son cruciales.
- Hudi CoW: Ideal para contextos donde la integridad de los datos es esencial, y se necesita una robusta recuperación de errores, especialmente en escenarios de ingestas en batch.
Referencias
Autores

Alberto Jaen
AWS Cloud Engineer
Empecé mi carrera laboral con el desarrollo, mantenimiento y administración de bases de datos multidimensionales y Data Lakes. A partir de ahí comencé a estar interesado en plataformas de datos y arquitecturas cloud, estando certificado 3 veces en AWS y 2 con Hashicorp.
Actualmente me encuentro trabajando como un Cloud Engineer desarrollando Data Lakes y DataWarehouses con AWS para un cliente relacionado con la organización de eventos deportivos a nivel mundial.
Alfonso Jerez
AWS Cloud Engineer
Apasionado de los datos y las nuevas tecnologías, especializado como AWS Cloud Engineer en la optimización de DataWarehouses y procesos de ingesta y transformación de Data Lakes. Motivado por la mejora continua y automatización de la integración de servicios.
Colaborando activamente con el grupo de Práctica Cloud en investigaciones y desarrollo de blogs de tecnologías punteras e innovadoras tales como esta, fomentando así el continuo aprendizaje.
Adrián Jiménez
AWS Cloud Engineer
Dedicado al aprendizaje constante de nuevas tecnologías y su aplicación, disfrutando de utilizarlas en la resolución de desafíos tecnológicos. Desarrollo mi carrera como Cloud Engineer diseñando, implementando y manteniendo infraestructura en AWS.
Colaboro activamente en la Práctica Cloud, donde investigamos y experimentamos con nuevas tecnologías, buscando soluciones para los retos que enfrentan nuestros clientes.
Navegación
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar





Footer
Patrono
Patrocinador

© 2024 Bluetab Solutions Group, SL. All rights reserved.