
Bluetab
an IBM Company
DataOps

Walter Talaverano
Microsoft Certified | Certified

Introducción
En bluetab llevamos años entendiendo los desafíos que enfrentan las organizaciones modernas para gestionar sus datos de forma eficiente y obtener valor de negocio. Con nuestra experiencia implementando proyectos de analytics e inteligencia artificial en distintas industrias, sabemos lo crucial que es adoptar un enfoque ágil en la gestión de datos y su gobierno.
En la era de los datos, las organizaciones se enfrentan al desafío de gestionar volúmenes crecientes de información para obtener conocimiento útil para el negocio. Sin embargo, los enfoques tradicionales de gestión de datos a menudo resultan lentos, propensos a errores y con poca colaboración entre equipos.
DataOps surge como una evolución necesaria en la forma en que las compañías abordan la gestión de datos. Basándose en los principios ágiles y de colaboración de DevOps, DataOps busca acelerar y mejorar los procesos relacionados con datos.
En este artículo exploraremos el concepto de DataOps, su contexto, beneficios y cómo llevarlo a la práctica en proyectos reales.
Definición de DataOps
DataOps es un conjunto de prácticas que buscan aumentar la agilidad y colaboración en los equipos de datos. Se basa en los principios y prácticas de DevOps adaptados a las necesidades específicas de los proyectos relacionados con datos.
DataOps pretende acabar con la separación que tradicionalmente existe entre los equipos de desarrollo, operaciones y análisis de datos. Para ello, busca mejorar la colaboración y comunicación entre estos, uniéndolos en torno a un objetivo común.
Al integrar prácticas ágiles, automatización y control de versiones provenientes de DevOps, DataOps permite a las compañías gestionar los datos de forma más eficiente y efectiva. Con DataOps se logra reducir sustancialmente el tiempo que transcurre entre la recolección de datos y su implementación en soluciones de negocio.
De esta manera, DataOps habilita una gestión ágil de los datos, donde éstos fluyen rápidamente entre los equipos. Los datos de calidad están disponibles de forma confiable para alimentar la toma de decisiones y la creación de valor para el negocio de forma continua.
Las características clave de DataOps incluyen:
- Automatización extrema de las tareas relacionadas con datos
- Colaboración entre todos los equipos involucrados en el proceso
- Control de versiones y trazabilidad para facilitar la identificación de problemas
- Integración y entrega continua con calidad
- Cumplimiento de las regulaciones y políticas organizacionales
En síntesis, DataOps busca mejorar la forma en que las organizaciones gestionan y utilizan los datos, promoviendo la agilidad, la colaboración y la automatización en todo el ciclo de vida de los datos. Esto brinda finalmente una entrega más rápida y confiable para la atención de las necesidades del negocio.
Contexto sobre la necesidad de DataOps en proyectos de datos
Tradicionalmente, los proyectos relacionados con datos han sido gestionados de forma manual y aislada. Los equipos de ingeniería, ciencia de datos e inteligencia de negocios trabajan en silos, lo que lleva a:
- Procesos propensos a errores al realizarse manualmente
- Retrasos en la entrega de valor al negocio
- Dificultad para rastrear el linaje de los datos
- Problemas de calidad de datos
- Reinvención de soluciones existentes
- Limitada colaboración entre equipos
Estas problemáticas se han vuelto más evidentes con el crecimiento exponencial en volumen y complejidad de los datos. Las organizaciones requieren aprovechar los datos de manera ágil para soportar la toma de decisiones.
DataOps surge como respuesta a estas necesidades, implementando prácticas probadas en ingeniería de software como DevOps. Permite gestionar los datos de manera ágil, confiable y eficiente.
Los beneficios de adoptar dataOps incluyen:
- Automatización de tareas manuales, reduciendo errores
- Entrega rápida de valor al negocio
- Trazabilidad y linaje de datos
- Democratización de datos de calidad
- Reutilización de soluciones
- Mejor colaboración entre equipos
- Toma de decisiones informada y ágil
Dado el veloz crecimiento en datos, DataOps se ha convertido en un imperativo para que las organizaciones puedan obtener valor de sus datos de forma eficiente y continua. Es una evolución necesaria en la forma en que se gestionan los proyectos relacionados con datos.
¿Cómo aplicar DataOps en un proyecto?
En bluetab tenemos amplia experiencia trabajando con clientes en la implementación de distintos servicios de manejo de datos, ayudándoles a adoptar prácticas maduras de DevOps. Sabemos que sin un enfoque adecuado, el uso de estas herramientas puede presentar desafíos en el control de versiones y flujos de despliegue.
Es por esto que guiamos a nuestros clientes en la aplicación de metodologías ágiles como GitFlow, lo cual les permite gestionar sus pipelines de datos de forma escalable y obtener valor de negocio de manera continua. Nuestro conocimiento y experiencia en DataOps permite a nuestros clientes maximizar el potencial de herramientas como en el caso que le presentamos a continuación.
Caso: Data Factory
Azure Data Factoryz (ADF) es una plataforma de integración de datos en la nube de Microsoft, que permite automatizar de forma flexible el movimiento y transformación de datos. Esta herramienta se ha vuelto muy popular en empresas para reemplazar los tradicionales ETL.
Sin embargo, la adopción de ADF no siempre se realiza aplicando las mejores prácticas de gestión. Errores comunes se relacionan con el control de versiones y los flujos de despliegue. Tradicionalmente, ADF se gestiona de la siguiente manera:
- Un único repositorio Git para todo el desarrollo
- La rama de publicación (adf_publish) se usa para despliegues a producción
- Una rama de colaboración (main/master) para el trabajo en equipo y para generar la rama de publicación
- Despliegues manuales a los distintos ambientes
Esta aproximación presenta limitaciones. Por ejemplo, no permite generar artefactos de ramas diferentes a la de colaboración. Esto dificulta la aplicación de parches rápidos a producción.
Para maximizar los beneficios de ADF, es recomendable implementar prácticas maduras de DevOps como GitFlow. Esto mejora el control de versiones, habilita entrega continua y facilita el despliegue y colaboración entre equipos. Adoptando estas metodologías, las organizaciones pueden gestionar ADF de forma ágil y escalable.
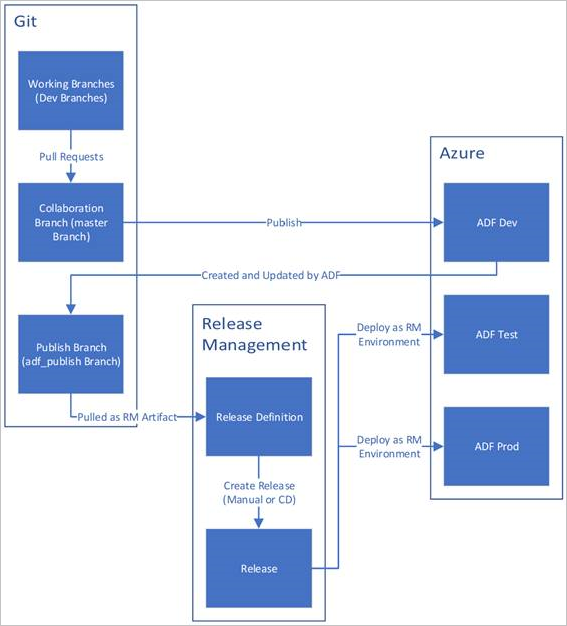
El trabajo simultáneo de múltiples ingenieros de datos sobre una misma instancia de Azure Data Factory puede ocasionar problemas si no se gestiona adecuadamente el flujo de colaboración y despliegue. Al realizar cambios sobre distintas ramas se pueden generar conflictos entre los desarrollos de diferentes miembros del equipo. Además, realizar modificaciones en la configuración cambiando la rama de publicación (adf_publish por defecto) o la de colaboración dificulta el seguimiento de la versión desplegada en producción.
Para evitar estas situaciones, es recomendable implementar un flujo de trabajo estandarizado como GitFlow. De esta manera se separan claramente las ramas de desarrollo y feature de las de entrega (release) y publicación (main). Así se reduce la fricción entre desarrolladores y se mantiene trazabilidad sobre lo implementado en el entorno productivo. La adopción de GitFlow promueve las buenas prácticas en el versionado y despliegue de Data Factory.
Es posible aplicar GitFlow a un DataFactory
Para ello se puede cambiar al siguiente flujo de trabajo:
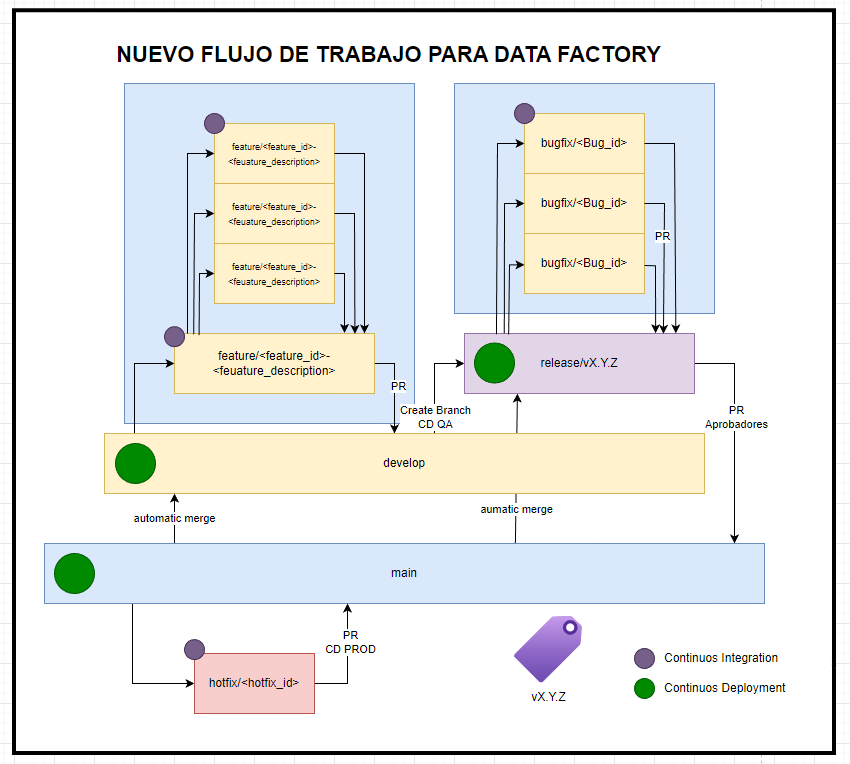
La imagen muestra un flujo de trabajo basado en GitFlow aplicado a Azure Data Factory. La rama «develop» se utiliza para colaboración y las ramas «feature» para el trabajo individual. Además, se incorporan las ramas «release» para manejar versiones candidatas a producción, y «hotfix» con «bugfix» para correcciones rápidas. Una mejora clave es el uso de tags para versionar la rama «main» con los cambios desplegados a producción.
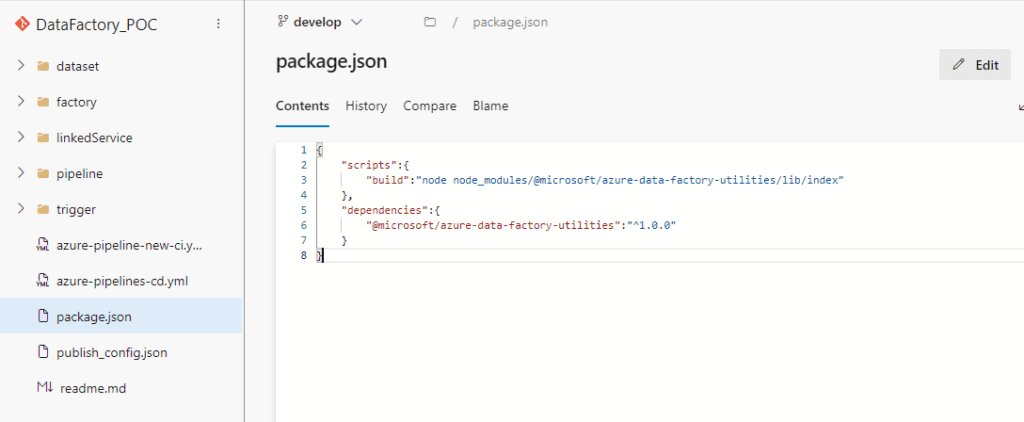
Esta implementación también incluye un flujo CI/CD independiente de las herramientas nativas de ADF. Los artefactos se generan a partir de una librería NPM configurada en el repositorio mediante el archivo packages.json:
{
"scripts":{
"build":"node node_modules/@microsoft/azure-data-factory-utilities/lib/index"
},
"dependencies":{
"@microsoft/azure-data-factory-utilities":"^1.0.0"
}
} De esta manera se mejora el control de versiones, trazabilidad y colaboración entre desarrolladores. El uso de prácticas recomendadas como GitFlow en ADF potencia la entrega continua de valor a través de un pipeline de CI/CD estandarizado.
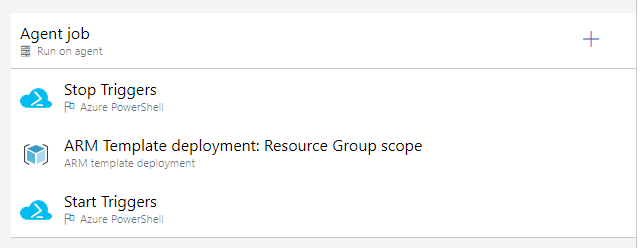
La librería /@microsoft/azure-data-factory-utilities/ permite validar y compilar el Data Factory, al compilar se obtiene como artefacto un ARM template que luego se despliega en los distintos ambientes.
Entonces el pipeline completo con el uso de esta librería se vería de la siguiente manera:
trigger:
branch:
include:
- develop
- main
- feature/*
- hotfix/*
- release/*
- bugfix/*
pool:
vmImage: 'ubuntu-latest'
steps:
# Installs Node and the npm packages saved in your package.json file in the build
- task: NodeTool@0
inputs:
versionSpec: '14.x'
displayName: 'Install Node.js'
- task: Npm@1
inputs:
command: 'install'
workingDir: '$(Build.Repository.LocalPath)' #replace with the package.json folder
verbose: true
displayName: 'Install npm package'
# Validates all of the Data Factory resources in the repository. You'll get the same validation errors as when "Validate All" is selected.
# Enter the appropriate subscription and name for the source factory. Either of the "Validate" or "Validate and Generate ARM temmplate" options are required to perform validation. Running both is unnecessary.
- task: Npm@1
inputs:
command: 'custom'
workingDir: '$(Build.Repository.LocalPath)' #replace with the package.json folder
customCommand: 'run build validate $(Build.Repository.LocalPath) /subscriptions/################'
displayName: 'Validate'
# Validate and then generate the ARM template into the destination folder, which is the same as selecting "Publish" from the UX.
# The ARM template generated isn't published to the live version of the factory. Deployment should be done by using a CI/CD pipeline.
- task: Npm@1
inputs:
command: 'custom'
workingDir: '$(Build.Repository.LocalPath)' #replace with the package.json folder
customCommand: 'run build export $(Build.Repository.LocalPath) /subscriptions/################ "ArmTemplate"'
displayName: 'Validate and Generate ARM template'
# Publish the artifact to be used as a source for a release pipeline.
- task: PublishPipelineArtifact@1
inputs:
targetPath: '$(Build.Repository.LocalPath)/ArmTemplate' #replace with the package.json folder
artifact: 'ArmTemplates'
publishLocation: 'pipeline'
Una vez obtenido el ArmTemplate del DataFactory se puede desplegar de forma automatizada con otro pipeline de despliegue, esto se puede realizar de la forma tradicional mediante releases de Azure Devops.
Lo que hemos presentado muestra los beneficios de adoptar prácticas ágiles de DevOps en la gestión de datos a través de DataOps. Hemos compartido un caso práctico de cómo aplicar metodologías maduras como GitFlow en Azure Data Factory, logrando un mejor control de versiones, colaboración entre equipos y entrega continua de valor.
Los invitamos a conocer Bluetab y nuestra experiencia en estas prácticas sustentadas en múltiples implementaciones en Perú y la región. Será un gusto poder asesorarlos en la automatización de sus procesos de datos, adoptando prácticas ágiles probadas que les permitirán obtener valor de sus datos de forma eficiente y continua. Juntos podemos diseñar una estrategia DataOps efectiva, customizada a sus necesidades específicas.
Walter Talaverano
Microsoft Certified | Certified
SOLUCIONES, SOMOS EXPERTOS
Te puede interesar





Footer
Patrono
Patrocinador

© 2024 Bluetab Solutions Group, SL. All rights reserved.