

Senior Cloud Solution Architect


Although it is true that Redshift was based on an older version of PostgreSQL 8.0.2, its architecture has changed radically and has been optimised over the years to improve performance for its strictly analytical use. So you need to:
When designing the database, bear in mind that some key table design decisions have a considerable influence on overall query performance. Some good practices are:
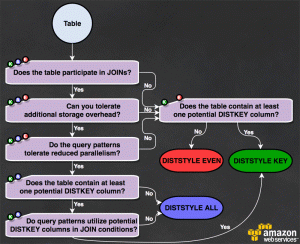
DISTKEY type. This will distribute the data to the various nodes grouped by the chosen key values. This will enable you to perform JOIN type queries on that column very efficiently.ALL type. It is advisable to copy those tables commonly used in joins of dictionary type to all the nodes. In that way the JOIN statement with much bigger fact tables will execute much faster.EVEN type. The data will be distributed randomly in this way.As Redshift is a distributed MPP environment, query performance needs to be maximised by following some basic recommendations. Some good practices are:
SELECT *. and include only the columns you need.WHERE statement to restrict the amount of data to be read.GROUP BY and SORT BY clauses so that the query planner can use more efficient aggregation.







