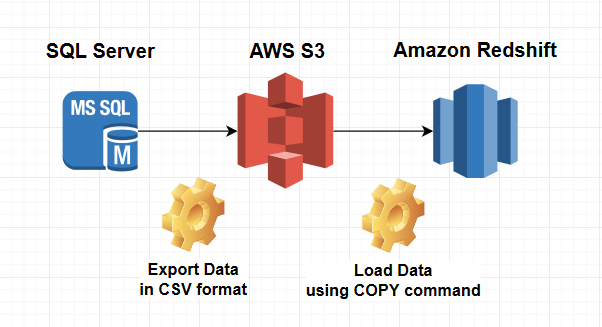
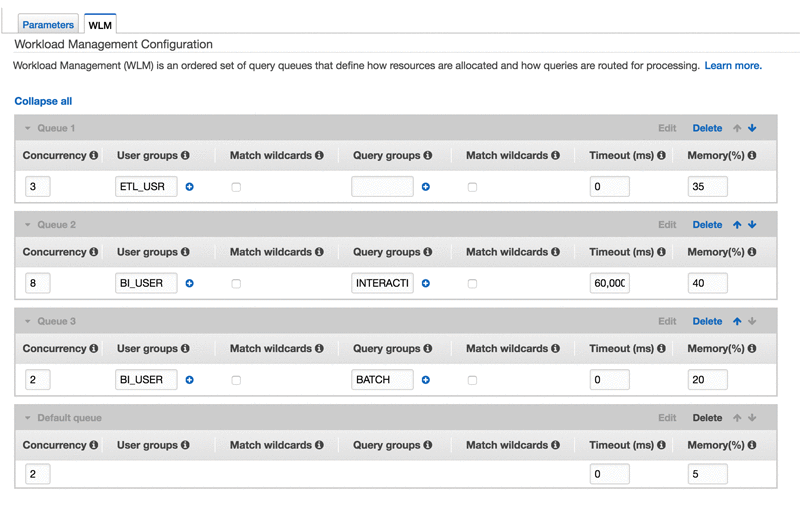
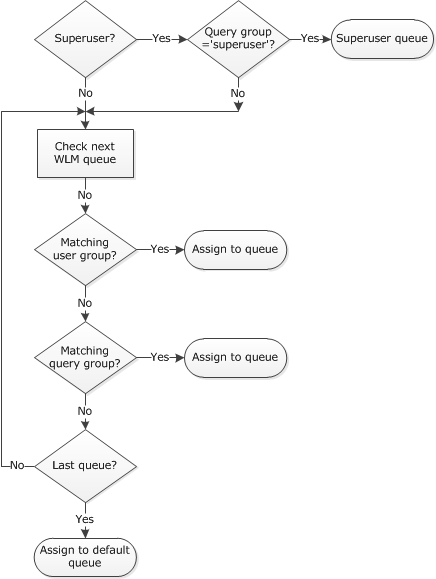
Senior Cloud Solution Architect


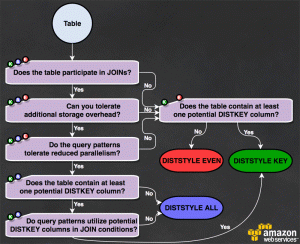
DISTKEY. De esta manera los datos se distribuirán en los diferentes nodos agrupados por los valores de la clave elegida. Esto te permitirá realizar consultas de tipo JOIN sobre esa columna de manera muy eficiente.ALL. Aquellas tablas que son comúnmente usadas en joins de tipo diccionario es recomendable que se copien a todos los nodos. De esta manera la sentencia JOIN realizada con tablas de hechos mucho más grandes se ejecutará mucho más rápido.EVEN. De esta forma los datos se distribuirán de manera aleatoria.SELECT *. e incluye solo las columnas que necesites.WHERE para restringir la cantidad de datos a leer.GROUP BY y SORT BY para que el planificador de consultas pueda usar una agregación más eficiente.